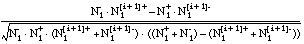Capítulo 6 :
Capítulo 6 :
Este trabajo presenta un sistema para aprendizaje de definiciones lógicas con incertidumbre, a partir de una base de datos relacional borrosa.
El campo de interés se centra, por tanto, en la programación lógica inductiva, introduciendo algunas interesantes aportaciones, principalmente en lo que se refiere a la entrada de datos y a los resultados producidos:
El punto de partida del trabajo lo constituye un sistema de inducción de definiciones lógicas bien conocido: FOIL, creado por Quinlan en 1992, basado en la lógica de predicados. Sobre este sistema inicial se realizan, además de las extensiones para lógica borrosa ya mencionadas, otra serie de modificaciones y ampliaciones enfocadas a mejorar la inducción de conocimiento. Estas mejoras se realizan, principalmente, en su parte heurística, al definir una función de evaluación de literales, basada en medidas de interés, que permite corregir algunas deficiencias del sistema original y aumentar la calidad de las reglas inducidas. Otras modificaciones se orientan hacia la introducción de conocimiento de base, mediante relaciones definidas intensionalmente, de modo similar a otros sistemas como FOCL.
Como resultado tangible de la tesis, se ha desarrollado y probado el sistema FZFOIL, disponible públicamente bajo la licencia GNU.
Con el sistema FZFOIL se consiguen mejorar las definiciones inducidas en algunos ejemplos con relaciones ordinarias, gracias a las modificaciones descritas en el (nuevas funciones de evaluación y conjuntos locales de tuplas proyectadas). Estas mejoras pueden considerarse como la eliminación de algunos máximos locales durante la exploración del espacio de búsqueda. Sin embargo, no se garantiza la eliminación de otros máximos locales, que pueden provocar nuevos errores en la inducción de conocimiento.
La extensión de la lógica de primer orden hacia una lógica borrosa de primer orden ( ) permite, en FZFOIL, ampliar el campo de aplicación, al poder trabajar sobre BD relacionales que incluyan relaciones ordinarias y/o borrosas. La posibilidad de utilizar literales borrosos extiende el espacio de búsqueda de literales, ya que se permite aplicar etiquetas lingüísticas sobre los mismos, aumentando así la potencia descriptiva de las definiciones.
Dentro del proyecto SEIC se han realizado diferentes pruebas de FZFOIL, todas sobre datos reales, para describir el comportamiento de los usuarios de un sistema de información ciudadana. Los resultados de estas pruebas ( ) han servido para comparar las definiciones obtenidas sin utilizar lógica borrosa y definiciones borrosas inducidas a partir de relaciones borrosas. La conclusión extraída sobre este punto es que la inducción de definiciones borrosas da lugar, generalmente, a mejores resultados.
El análisis de la complejidad de FZFOIL demuestra que, aunque el espacio de búsqueda de literales crece algo más al existir relaciones borrosas (debido a las etiquetas lingüísticas de los literales borrosos), el tamaño del conjunto de entrenamiento no varía. Por el contrario, la complejidad de FZFOIL al ser aplicado sobre BD sin relaciones borrosas se simplifica, debido a la reducción del número de tuplas que es necesario evaluar (al trabajar con conjuntos de tuplas proyectadas).
Puede ser interesante estudiar la incorporación de nuevas condiciones que debe cumplir la función de evaluación de literales Interés. Por ejemplo, que el interés de una regla decrezca al aumentar su complejidad ( [EC. 3.4] ), para favorecer la construcción de definiciones más cortas.
Otras posibilidades, algunas ya mencionadas en el apartado 3.3.1 , son: costes especiales asignados al uso de ciertos predicados, coste por número de variables utilizadas en una cláusula, etc.
Merece la pena destacar otra alternativa interesante: aplicar la función de evaluación Interés no a literales candidatos sino a cláusulas parcialmente construidas. De este modo, se abren nuevas posibilidades para la exploración del espacio de búsqueda, como se propone en el siguiente apartado ( 6.2.1.2 ).
Es inmediato adaptar la función RI para calcular el interés de una cláusula de Horn C i-1 , mediante la siguiente asignación de A y B:
resultando los siguientes argumentos, medidos en T1:
N = N1+ + N1- número total de tuplas de T1
NA = N1[i+1]+ + N1[i+1]- número de tuplas (+ y -) de T1 que satisfacen L1 ... Li
NB = N1+ número de tuplas de T1 que satisfacen el literal objetivo P
NAB = N1[i+1]+ número de tuplas de N1 que satisfacen P y L1 ... Li
La expresión [EC. 3.3] aplicada sobre estos argumentos queda del siguiente modo:
de este modo pueden evaluarse cláusulas candidatas en vez de literales candidatos. Esto abre la posibilidad de construir cláusulas por otros métodos, diferentes de la sucesiva evaluación y anexión del mejor literal candidato.
El algoritmo de búsqueda de descripciones utilizado en FOIL corresponde a un algoritmo del tipo "primero el mejor" (también denominado de "corta vista"), ya que, en cada iteración, selecciona el mejor literal candidato y lo añade a la cláusula en construcción. Además, establece algunos puntos de retroceso, en los que se puede bifurcar la búsqueda en caso de que por la rama elegida no se llegue a una definición válida ( apartado 2.5.4.5 ).
Este algoritmo presenta, como ya se ha mencionado, algunas limitaciones importantes:
Este problema se debe a que, durante la evaluación de literales candidatos se selecciona siempre el mejor de ellos, descartando otros que, aun siendo peores inicialmente, pueden dar lugar a mejores definiciones en iteraciones posteriores. Los puntos de retroceso establecidos en FOIL no son siempre suficientes para garantizar la mejor definición y pueden presentarse problemas como los analizados en el . En este capítulo también se proponía una nueva función de evaluación de literales (Interés*), en sustitución de la original (Ganancia); de este modo se solventaban diferentes errores, posibles causantes de máximos locales, aunque no se garantizaba la eliminación de los mismos.
Como se deduce del análisis de la complejidad de FOIL ( apartado 5.4 ), la construcción de nuevas cláusulas puede tener asociada una complejidad muy grande, especialmente en cláusulas con muchas variables. Muchas veces los heurísticos de poda aplicados ( apartado 2.5.4.3 ) no son lo bastante eficientes como para limitar ésta suficientemente, y el coste de la búsqueda crece excesivamente.
Se han realizado algunos esfuerzos a solucionar el problema de los máximos locales mediante nuevos algoritmos de búsqueda ("algoritmo de los estados provisionales" de [Serrano, 95] ). Estos algoritmos se basan en la exploración del espacio de búsqueda con uno o dos niveles de profundidad a partir de algunos literales. En algunos ejemplos se conseguía mejorar los resultados obtenidos, aunque en otros no sólo no se mejoraba, sino que el tiempo de ejecución crecía considerablemente. En cualquier caso, este algoritmo tampoco garantiza la eliminación de máximos locales.
Para simplificar la complejidad de la búsqueda, algunos sistemas, como INDUCE ( [Dietterich y Michalski, 84] ) o RDT/DB ( [Morik y Brockhausen, 97] ), realizan una búsqueda en dos pasos, mediante la partición del espacio de descripciones en dos niveles (denominados de sólo estructura y de atributos en INDUCE). Adaptando esta idea a sistemas de ILP, podría simplificarse la complejidad de la construcción de definiciones.
Otro enfoque que se plantea (que puede coexistir con la "búsqueda en dos niveles") es la posibilidad de usar algoritmos de búsqueda paralela, que mejoren los resultados ante el problema de los máximos locales y cuya complejidad crezca de forma controlada. Siguiendo esta línea, puede pensarse en la utilización de algoritmos genéticos para explorar el espacio de descripciones.
La utilización de algoritmos genéticos representa una estrategia de búsqueda alternativa, que permite evitar algunas de las principales deficiencias de la búsqueda de "corta vista" o "hill-climbing" usada en FOIL, como la caída en máximos locales. Al mismo tiempo, resulta más eficiente que la búsqueda exhaustiva. El inconveniente de estos métodos es que no garantizan que se encuentre la solución óptima, aunque suelen dar buenos resultados.
En la literatura pueden encontrarse algunos sistemas que utilizan algoritmos genéticos para construir definiciones:
Para abordar la búsqueda de descripciones con un algoritmo genético se propone construir una población de cláusulas de Horn candidatas, todas con la misma cabeza, en la que se apliquen operadores genéticos de selección (aleatoria o ponderada por el valor de evaluación de los individuos), entrecruzamiento (intercambio de antecedentes entre pares de cláusulas) y mutación (modificación de algún antecedente de una cláusula). De este modo, se generan nuevos individuos en la población (nuevas cláusulas), algunos de los cuales mejorarán las descripciones obtenidas.
Para poder evaluar las diferentes cláusulas candidatas, se puede adaptar fácilmente la función de evaluación Interés para su utilización con cláusulas ( [EC. 6.1] ).
La lógica de predicados ofrece una gran potencia descriptiva, aunque generalmente en los sistemas de programación lógica inductiva, en particular en FOIL, se emplea una versión restringida de la misma, ya que no se permite la utilización de funciones dentro de las definiciones lógicas.
En FZFOIL se extiende la potencia descriptiva de la lógica de predicados hacia la lógica borrosa de predicados, permitiendo describir relaciones borrosas (y ordinarias) a partir de otras relaciones (borrosas u ordinarias), y calificar los literales borrosos con etiquetas lingüísticas. Sin embargo, las cláusulas construidas tampoco permiten la utilización de funciones.
Por otro lado, FOIL es incapaz de aumentar su vocabulario mediante la invención de nuevos predicados. En FZFOIL ocurre lo mismo, a pesar de que la utilización de etiquetas lingüísticas permite modificar, en cierta medida, el significado de los predicados borrosos.
Podría resultar de interés extender la potencia descriptiva de FZFOIL en ambas direcciones: por un lado, incorporar la utilización de funciones en las definiciones, y por otro, considerar la posibilidad de inventar nuevos predicados. Existen sistemas de ILP, como SIERES ( [Wirth y O'Rorke, 91] ) o CHILLIN ( [Zelle et al., 94] ), que incorporan ambas facilidades, aunque, por otro lado sufren de otras importantes limitaciones (manejo de datos ruidosos, definiciones recursivas, atributos sin tipo asignado, etc.).
En el sistema FZFOIL desarrollado se permite introducir relaciones borrosas, en las que sus tuplas tienen asignado un grado de pertenencia. A partir de estas relaciones se construyen literales borrosos, eventualmente con etiquetas lingüísticas, para construir las definiciones lógicas. Este esquema se ajusta a algunos modelos propuestos para bases de datos relacionales borrosas (modelo de Umano, apartado 2.6.4.2 ), aunque algunos otros (modelo de Buckles y Petry, o modelo de Medina) añaden la borrosidad a los atributos, considerando los dominios como conjuntos borrosos.
En FZFOIL se permite utilizar atributos borrosos en las relaciones de la base de datos, aunque no se consideran más que como valores de un dominio de tipo nominal, ya que, a través del grado de pertenencia de la correspondiente tupla, no es posible distinguir unos de otros. Lo mismo ocurre cuando estos atributos se utilizan como constantes dentro de un literal borroso, en una definición.
Resultaría interesante poder manejar estos valores borrosos como tales, desde el punto de vista semántico, de modo que, en las definiciones construidas, se pudiesen utilizar relaciones de equivalencia establecidas para sus dominios. En algunos modelos de base de datos relacional borrosa (Buckles y Petry) se permiten definir estas clases de equivalencia, que indican la similitud entre diferentes etiquetas de un dominio borroso.
En el modelo de Medina ( [Medina et al., 94] ) lo que se propone es la utilización de diferentes formas de representar la incertidumbre en los atributos de una relación: mediante distribuciones de posibilidad, etiquetas lingüísticas, funciones, etc. Extender la funcionalidad de FZFOIL en este sentido, para manejar "relaciones borrosas generalizadas", como las del modelo mencionado, aumentaría la complejidad del algoritmo (el espacio de búsqueda de literales crecería considerablemente), aunque también aumentaría la potencia descriptiva de las definiciones borrosas. En cualquier caso, sería interesante disponer de resultados de este tipo para evaluarlos de forma precisa.
Aunque sistemas como FOIL, FZFOIL, etc. ya han demostrado su validez en algunos ejemplos reales, es indudable que aún requieren un gran esfuerzo del ingeniero de conocimiento. El éxito de estos sistemas está, muchas veces, en la forma en que se seleccionan, preprocesan y filtran los datos de partida. Pero quizá la limitación más importante está en que se trata de sistemas de aprendizaje inductivo con ejemplos ( apartado 2.3.2.2 ), en los que es necesario especificar la relación o relaciones objetivo, para las que se quieren construir definiciones lógicas.
Resulta mucho más prometedora la sugerencia de convertir estos sistemas en otros capaces de realizar descubrimiento en bases de datos. Un sistema de descubrimiento resulta más interesante, al permitir obtener definiciones generales a partir de las relaciones almacenadas en la base de datos, sin conocer a priori cuál es la relación objetivo. Una sugerencia más ambiciosa es que, además, se puedan formar conceptos, entendiendo como tales subconjuntos interesantes de alguna relación, con definiciones lógicas sencillas construidas a partir de otras relaciones. Siguiendo esta línea hay que mencionar algunos sistemas como CHILLIN ( [Zelle et al., 94] ), CIGOL ( [Muggleton y Buntime, 88] ), etc., capaces de inventar nuevos predicados.