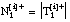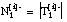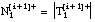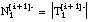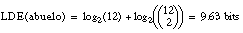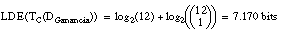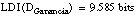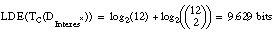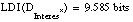Capítulo 3 :
Capítulo 3 :
Una de las principales deficiencias de FOIL es que la búsqueda que realiza dentro del espacio de literales candidatos podría calificarse de corta vista, ya que selecciona el mejor de los literales explorados, sin tener en cuenta otras posibilidades que podrían dar mejores resultados globales en pasos posteriores. Este método de búsqueda es sencillo, pero los resultados que genera no son siempre lo suficientemente buenos, debido a los máximos locales (tan conocidos en cualquier sistema de optimización) que se producen en muchas ocasiones. Con frecuencia las definiciones que se construyen son complicadas, con más cláusulas o con cláusulas más largas de lo necesario, e incluso, a veces, no se encuentra ninguna definición completa y consistente aunque realmente exista.
Durante el proceso de construcción de definiciones tiene gran importancia no sólo el algoritmo de búsqueda (de corta vista en FOIL), sino también la función de evaluación de literales que se emplee (ganancia en FOIL). La forma de esta función de evaluación puede determinar, precisamente, la existencia o no de máximos locales.
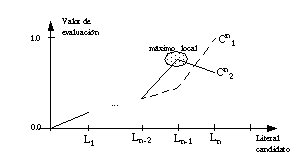
Aunque FOIL incorpora algunos sencillos mecanismos de retroceso (backtracking), éstos sólo se disparan cuando, durante la construcción de una cláusula, se llega a un estado sin soluciones (sin literales que mejoren la cláusula en construcción) y en algún paso previo se haya realizado un selección "arbitraria" de un literal (cuando existen varios con un valor de ganancia igual o similar). Estos mecanismos no son suficientes para evitar los máximos locales, y se producen errores durante la construcción de las cláusulas.
Cabe mencionar aquí otro algoritmo de Quinlan: ID3 ( [Quinlan, 86] ), que, al igual que FOIL, realiza una búsqueda heurística basada en una medida de la ganancia de información (reducción de entropía).
El objetivo de ID3 (construcción de un árbol de decisión con un lenguaje que puede asimilarse a la lógica de proposiciones extendida, apartado 2.3.1.1 ) es diferente del de FOIL, así como la función ganancia empleada. Sin embargo, también se han detectado algunas deficiencias en esta última. En el caso de ID3, la medida de ganancia utilizada favorece a los atributos con más valores. Quinlan propuso dividirla por un factor de ganancia (Gain Ratio), para mitigar este efecto, aunque esto presenta otras nuevas limitaciones. En [López de Mántaras, 91] se propone una nueva función para seleccionar atributos, dentro de ID3, basándose en una medida de la distancia entre las particiones (definidas por los valores de cada atributo), con la que se mejoran los resultados de ID3.
En los siguientes apartados se analizarán diferentes errores producidos por la ganancia utilizada en FOIL, que pueden dar lugar a máximos locales, y se propondrá una nueva función de evaluación para solventarlos. Aunque esta nueva función, basada en medidas del interés de una regla, no garantiza la eliminación de máximos locales, al menos corrige las deficiencias detectadas en la medida de la ganancia, mejorando los resultados en diferentes ejemplos.
Otro método de abordar el problema de los máximos locales consiste, como ya se ha mencionado, en la exploración del espacio de búsqueda mediante nuevos algoritmos, aunque esta vía se deja abierta como futura línea de investigación ( apartado 6.2.1.2 ).
El valor de la función Ganancia ( apartado 2.5.4.1 ) depende únicamente de la información de los conjuntos Ti y Ti+1 (función de la concentración de tuplas positivas) y del número de tuplas positivas de Ti que satisfacen al literal candidato Li (es decir, Ni++). Esto hace que, en algunas ocasiones, este valor no se corresponda con la bondad de un literal, considerando que ésta debe reflejar la capacidad de la definición para cubrir de forma completa y consistente el conjunto de entrenamiento inicial; además, deben preferirse las definiciones sencillas, esto es, de mínima longitud (suponiendo que la longitud, definida en ecuación [EC. 2.26] , puede ser una medida de la complejidad).
Hemos detectado tres tipos de errores que pueden ocurrir al evaluar los literales con la función Ganancia, tal y como se describe a continuación; sus consecuencias pueden ser las mismas: desde un simple incremento en la complejidad de la definición hasta la construcción de definiciones inexactas. Algunos resultados preliminares ya fueron presentados en [Gómez, 92] .
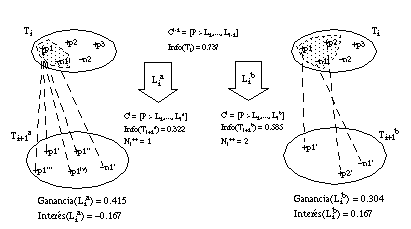
El valor de la función Ganancia es insensible al número de tuplas negativas cubiertas. Supongamos la situación descrita en la figura 3-2 : tenemos el conjunto Ti (con tres tuplas positivas: p1, p2 y p3, y dos negativas: n1 y n2), y estamos evaluando dos literales candidatos Lia y Lib; ambos literales cubren las mismas tuplas positivas (p1 y p2), y generan nuevos conjuntos con igual información (con cuatro tuplas positivas y dos negativas). La única diferencia es que sólo una tupla negativa de Ti satisface Lib, mientras que son dos las tuplas negativas que satisfacen Lia.
Sería lógico suponer que, a igualdad de tuplas positivas cubiertas, deberían favorecerse los literales satisfechos por menos tuplas negativas (es decir, Lib); sin embargo, la función Ganancia no diferencia entre ambos en situaciones como la del ejemplo.
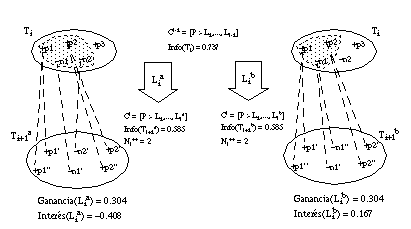
Una elección incorrecta en situaciones de este tipo puede no tener ninguna consecuencia en el resultado final del algoritmo, aunque, en el caso peor, puede dar lugar a una definición más larga de lo necesario o, incluso, una definición incompleta (si se llegase a superar la longitud de descripción extensional). Por ello, una cláusula inconsistente en la que haya tenido lugar algún error de este tipo tendrá mayor probabilidad de ser rechazada, finalizando entonces la construcción con una definición incompleta. Pero, incluso si eligiendo el literal que genera la cláusula más precisa (Lib) tampoco se evita la existencia de una definición incompleta, al menos ésta cubrirá menos tuplas negativas del conjunto inicial, por lo que el error producido será menor.
La función Interés (que estudiaremos más adelante) sí tiene en cuenta el número de tuplas negativas cubiertas, de modo que puede diferenciar entre ambos literales y elegir correctamente el que proporciona mayor precisión.
En algunas ocasiones la función Ganancia no es proporcional al número de tuplas positivas cubiertas. Esto ocurre cuando el grado en que se expanden las tuplas del conjunto local difiere en gran medida para diferentes literales candidatos. Podemos ver esta situación en el ejemplo descrito en la figura 3-3 :
Usando como heurístico de evaluación la función Ganancia, se pueden elegir literales (como Lia en este ejemplo) que cubran menos tuplas positivas (e igual o mayor número de tuplas negativas) que otros candidatos, favoreciendo así la construcción de cláusulas demasiado específicas, es decir, con conjuntos cubiertos pequeños. Esto obliga a que las definiciones construidas necesiten más cláusulas para cubrir completamente el conjunto de ejemplos de entrenamiento, lo que repercute en un incremento en la complejidad de las definiciones (medida por su longitud de codificación) y, posiblemente, también un incremento en el coste asociado a su construcción (coste de la búsqueda de literales). Por ello, situaciones como la descrita pueden considerarse como errores de evaluación de literales.
Pero el mayor problema aparece, de nuevo, cuando la cláusula supera la longitud de codificación máxima permitida y, consecuentemente, se pone en marcha el heurístico que permite la existencia de definiciones inexactas. En este caso, la cláusula construida con el literal erróneo tendrá menor precisión que la otra alternativa y, por tanto, menor probabilidad de ser añadida a la definición correspondiente (en el supuesto de que se permita su inconsistencia), tal y como vimos en el apartado 2.5.4.5 . Por el contrario, si la elección del literal fuera la otra (usando un heurístico como el Interés, tal y como veremos), y también finalizara la construcción de la cláusula (inconsistente), sería más probable superar el umbral de precisión necesario, construyéndose así una definición completa (o, al menos, que cubra más tuplas positivas).
No debemos olvidar que las tuplas positivas que se quieren cubrir con la definición construida no son las del conjunto local Ti, sino las del conjunto inicial T+. Por tanto, al aplicar el heurístico de evaluación Ganancia sobre los argumentos medidos en los sucesivos Ti, estamos introduciendo errores en la evaluación de los literales, ya que los resultados calculados sólo reflejan de manera indirecta el comportamiento real de los candidatos.
Dos literales que cubran un mismo número de tuplas positivas y negativas en uno de los conjunto intermedios Ti deberían tener diferente valor de evaluación si los correspondientes conjuntos cubiertos (medidos sobre el conjunto inicial T1) no coinciden. En la función Ganancia, tal como se ha definido, esto no es así, por lo que se puede producir un error que hemos denominado de tipo III, al medir argumentos que no representan a los del conjunto cubierto. Podemos ver de forma gráfica este problema en la figura 3-4 :
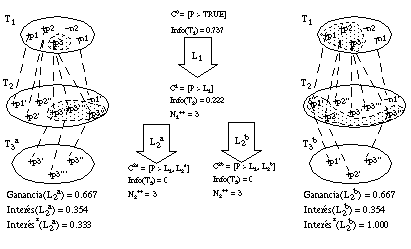
Usando heurísticos de evaluación que midan sus argumentos sobre los conjunto intermedios (por ejemplo, la función Ganancia, o la función Interés, tal y como veremos más adelante), no podemos prevenir que ocurran errores de este tipo, ya que los valores resultantes son iguales para ambos candidatos. Sin embargo, es posible realizar las medidas sobre el conjunto inicial (T1), proyectando sobre él los sucesivos conjuntos intermedios (Ti, i >1); en este caso la función Interés (que hemos denominado Interés* para diferenciarla), tomaría valores más acordes con el conjunto cubierto: 1.0 para el caso de la cláusula completa, y 0.333 para la otra opción. Veremos más adelante cómo medimos el valor Interés* a partir de la función Interés.
Podemos construir un heurístico que permita evaluar los literales candidatos y prevenga los errores detectados en la función Ganancia. Para ello nos basaremos en medidas del interés de una regla lógica, tal y como se describe en [Piatetsky-Shapiro, 89] para la función RI (Rule Interest).
La función RI, a diferencia de la Ganancia, no se basa en la teoría de la información (no mide la información aportada por cada tupla positiva dentro del conjunto de entrenamiento), sino que mide el interés de una regla lógica de la forma AÆB, en función del número de casos cubiertos por el antecedente (A) y el consecuente (B).
Para una regla AÆB denominaremos:
N al tamaño (número de tuplas) del conjunto de entrenamiento,
NA al número de hechos que satisfacen el antecedente A,
NB al número de hechos que satisfacen el consecuente B,
NAB al número de hechos que satisfacen simultáneamente A y B.
Se puede llegar a la función RI a partir de las características que deseamos en ella, para luego construirla "a la medida". Por ejemplo, algunas condiciones que debe cumplir RI son:
y teniendo en cuenta las siguientes igualdades:
podemos deducir la condición equivalente:
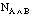 si los demás parámetros son constantes.
si los demás parámetros son constantes.Se puede comprobar que la función más sencilla que cumple estas cuatro condiciones es:
que, intuitivamente, puede ser interpretada como la diferencia entre el número real de tuplas para las que se satisfacen A y B (i.e. ) y el número esperado de tuplas que se satisfarían si A y B fuesen estadísticamente independientes.
Otra función que cumple las cuatro condiciones anteriores y, además, tiene la ventaja de estar normalizada (acotada en el intervalo [-1, 1]) es la expresión:
que no es más que una medida de la correlación 1 entre A y B.
Puede ampliarse el conjunto de condiciones que debe cumplir la función RI; por ejemplo, incluyendo la siguiente condición:
Una posible expresión que satisface esta condición, además de las cuatro anteriores, es la siguiente:
El establecimiento de nuevas restricciones para la función RI (por ejemplo, añadiendo costes al uso de ciertos predicados, o limitando el número de nuevas variables en cada cláusula) deja abierta una posible línea de investigación.
La expresión que utilizaremos a partir de aquí para referirnos al interés de una regla será la de la ecuación [EC. 3.3] .
En principio RI ( ecuación [EC. 3.3] ) es aplicable directamente a reglas lógicas de la forma AÆB, que pueden pertenecer a la lógica de proposiciones o a la lógica de predicados de primer orden. Esta medida permite seleccionar el mejor antecedente A para un consecuente dado B.
Podemos adaptar la función RI para su uso como heurístico de evaluación de literales en FOIL. Para ello, será necesario expresar las cláusulas que se construyen en la forma AÆB, siendo A el literal que se desea evaluar, y B la cláusula en construcción (antes de añadir el literal candidato).
Dada una cláusula de Horn con cabeza:
equivalente a la expresión lógica:
podemos transformarla con las siguientes equivalencias:
De este modo, conseguimos una expresión de la formay el interés de AÆB permitirá evaluar los literales Li candidatos para construir la cláusula Ci.
Obsérvese que la expresión de B es la cláusula 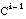 (formada por los literales L1, L2,..., Li-1), construida en la iteración anterior del algoritmo de construcción de cláusulas de FOIL:
(formada por los literales L1, L2,..., Li-1), construida en la iteración anterior del algoritmo de construcción de cláusulas de FOIL:
por lo que las tuplas + y - de Ti (tal como se definió en el apartado 2.5.3.2 ) serán, respectivamente, ejemplos y contraejemplos de B.
Estrictamente hablando, la condición lógica representada por B implica que, además de las tuplas positivas de Ti, las tuplas que no satisfacen los antecedentes de también satisfarían B (serían ejemplos de B), aunque, en la práctica, no serían de utilidad para seleccionar Li, por lo que no las tendremos en cuenta.
Del mismo modo, restringiremos las tuplas que satisfacen A a las que satisfacen Li dentro del conjunto Ti, de modo que Ti servirá como conjunto local de entrenamiento para construir Ci a partir de .
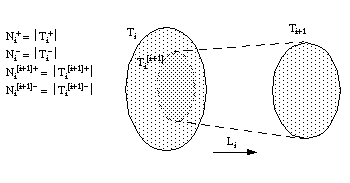
Si denominamos  al subconjunto de tuplas de Ti que satisfacen Li, es decir:
al subconjunto de tuplas de Ti que satisfacen Li, es decir:
tal y como se indica en la figura 3-5 , el valor de los argumentos de RI será el siguiente:
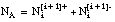 número de tuplas (+ y -) de Ti que satisfacen Li
número de tuplas (+ y -) de Ti que satisfacen Li
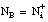 número de tuplas de Ti que satisfacen la cláusula (aplicando
[EC. 2.6]
se reduce a las tuplas + de Ti)
número de tuplas de Ti que satisfacen la cláusula (aplicando
[EC. 2.6]
se reduce a las tuplas + de Ti)
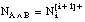 número de tuplas de Ti que satisfacen Li y (se reduce a las tuplas + de Ti que satisfacen Li)
número de tuplas de Ti que satisfacen Li y (se reduce a las tuplas + de Ti que satisfacen Li)
Aplicando la ecuación [EC. 3.3] sobre estos argumentos se obtiene la siguiente expresión para el interés de un literal Li:
Esta misma ecuación puede expresarse en función de los argumentos usados para el cálculo de la Ganancia (ecuaciones [EC. 2.29] y [EC. 2.28] ):
resultando la siguiente expresión:Con esta función se solucionan algunos de los errores descritos en el apartado 3.2 :
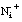 ), por ello puede corregir el error de tipo I, como se ilustra en la
figura 3-2
.
), por ello puede corregir el error de tipo I, como se ilustra en la
figura 3-2
.Sin embargo, como sus argumentos son medidos sobre el conjunto local Ti, tampoco diferencia entre los candidatos de la figura 3-4 . La solución a este último error se trata a continuación.
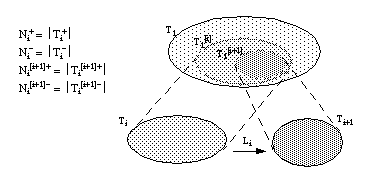
Para solucionar el problema de tipo III es necesario definir un nuevo conjunto de tuplas para la búsqueda de Li. Este conjunto debe ser un subconjunto de T1 para que los argumentos que midamos en él sean representativos del conjunto cubierto por la cláusula.
Obtendremos este nuevo conjunto proyectando el conjunto intermedio Ti sobre el conjunto inicial T1, y lo llamaremos 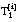 (ver
figura 3-6
). Es decir, es el conjunto cubierto por la cláusula en construcción . Se cumple que:
(ver
figura 3-6
). Es decir, es el conjunto cubierto por la cláusula en construcción . Se cumple que:
Este conjunto será diferente para cada uno de los literales que se añaden a la cláusula en construcción, del mismo modo que varían los conjuntos intermedios Ti. Para el primer literal de una cláusula, coincidirá con el conjunto de entrenamiento de la cláusula (T1):
Podemos aplicar la misma función RI sobre estos nuevos conjuntos, razonando de modo similar a como hicimos en el apartado anterior, para evaluar los literales candidatos durante la construcción de una cláusula.
tendremos los siguientes argumentos, medidos en :
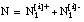 número total de tuplas de T1[i]
número total de tuplas de T1[i]
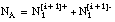 número de tuplas (+ y -) de
número de tuplas (+ y -) de 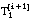 (satisfacen Li)
(satisfacen Li)
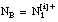 número de tuplas de que satisfacen cláusula
número de tuplas de que satisfacen cláusula
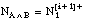 número de tuplas de
número de tuplas de 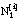 que satisfacen Li y (se reduce a las tuplas + de )
que satisfacen Li y (se reduce a las tuplas + de )
La expresión [EC. 3.3] aplicada sobre estos argumentos queda del siguiente modo:
Con esta función se solucionan todos los errores descritos en el apartado 3.2 :
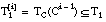 también se corrige el error de tipo III (
figura 3-4
).
también se corrige el error de tipo III (
figura 3-4
).En muchos de los ejemplos analizados no se produce ninguno de los errores descritos para la función Ganancia, de modo que no existe diferencia entre las definiciones inducidas con uno u otro heurístico de evaluación. Sin embargo, en algunas ocasiones, las consecuencias de estos errores resultan bastante notables, como veremos a continuación.
En este ejemplo, presentado por primera vez en [Gómez y Fernández, 92] , podemos ver un caso extremo de cómo puede afectar el heurístico de evaluación a las definiciones inducidas. Dependiendo de qué función se emplee para evaluar los literales candidatos, se construirá una definición sencilla, más compleja, o incluso no se podrá construir ninguna válida.
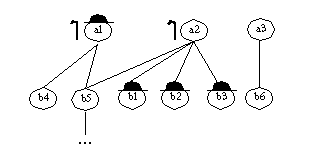
Supongamos la siguiente base de datos, con información sobre diversos atributos de un conjunto de personas: estar enfermo, tener barba y ser fumador; y relaciones existentes entre ellas: ser padre de alguien o ser jefe de alguien. Los atributos se representan por relaciones unarias en la base de datos, mientras que las relaciones entre personas son binarias:
En las siguientes figuras se representa esta misma información de forma gráfica. Para representar a las personas "enfermas" se ha sombreado su cara; los atributos "fumador" y "barbudo" se indican con una pipa y una barba de chivo respectivamente. Las relaciones binarias se indican mediante líneas verticales en la figura 3-7 ("padre_de") y figura 3-8 ("jefe_de"); que deben leerse de arriba a abajo, para interpretar correctamente la semántica de "a es padre de b" o "a es jefe de b" respectivamente.
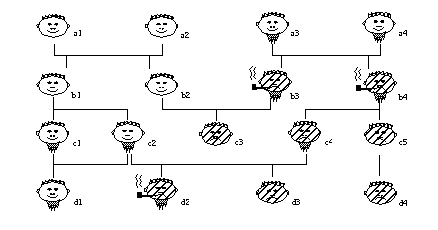
Supongamos que queremos encontrar una definición lógica para la relación enfermo, usando relaciones existentes en la base de datos (puede intentarse este ejercicio manualmente, inspeccionando las figuras figura 3-7 y figura 3-8 ). Usando FOIL, se introducirían las relaciones definidas anteriormente como dato de entrada, indicando que enfermo debe ser el predicado objetivo. Las tuplas + serán por tanto las personas enfermas, y las negativas las no enfermas:
Según utilicemos como heurístico para evaluar los literales la función Ganancia, la función RI o la función RI*, el sistema FOIL inducirá una definición diferente.
Si estudiamos en detalle las definiciones construidas, observamos que ya en el primer literal de la primera cláusula se produce la primera diferencia, ya que con la función Ganancia el literal elegido es jefe_de(V2, X1), mientras que con las funciones RI y RI* es padre_de(V2, X1), según puede verse en la figura 3-9 .
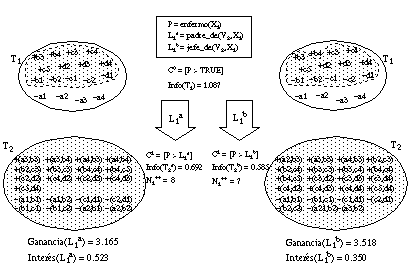
Como puede observarse, la diferencia en este caso se debe a un error de tipo II, pues el literal jefe_de(V2, X1) cubre menos tuplas + que padre_de(V2, X1) y, sin embargo, produce un conjunto T2 con mayor concentración de tuplas + (es decir, con menor información).
En este ejemplo, la función Ganancia favorece erróneamente a jefe_de(V2, X1), mientras que las funciones RI y RI* permiten elegir al mejor literal padre_de(V2, X1).
Si continuamos la ejecución utilizando las funciones RI y RI*, encontramos una nueva diferencia en la búsqueda del siguiente literal ( figura 3-10 ). Esta diferencia se debe a un error de tipo III, por el cual el literal barbudo(V2), que cubre más tuplas en el conjunto T2, se ve favorecido por RI frente al literal enfermo(V2), a pesar de que este último cubra más tuplas del conjunto inicial T1. Con la función RI* se previene este error y se selecciona correctamente el literal enfermo(V2).
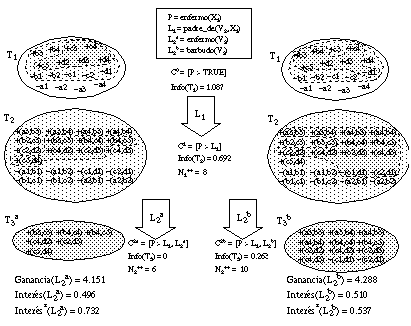
Para finalizar esta discusión, vamos a comparar los resultados que se obtienen en este ejemplo usando los diferentes heurísticos de evaluación de literales:
enfermo(X1) :- jefe_de(V2, X1), enfermo(V2), ¬fumador(V2)
enfermo(X1) :- jefe_de(V2, X1), enfermo(V2), padre_de(V2, X1)
Como puede verse a simple vista, la definición DGanancia es la peor de las tres, ya que es la más compleja; de hecho, debería finalizar su construcción sin incluir su última cláusula, tal y como se ha indicado, resultando así una definición incompleta. La definición DInterés es más sencilla, lo que permite que se construya cumpliendo las condiciones de completitud y consistencia. Sin embargo, la mejor definición es la que se obtiene con el heurístico Interés*: "los enfermos son hijos de enfermos o son fumadores".
Si consideramos que la complejidad de una definición se puede medir por el número de bits necesarios para codificarla ( apartado 2.5.2.9 ), tendremos los siguientes valores:
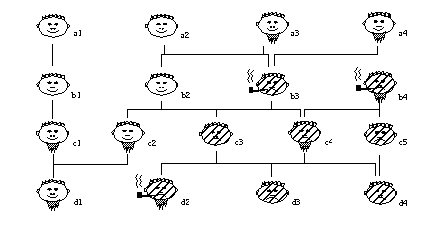
Por tanto, con la función Interés* no sólo se produce una importante simplificación (ahorro de bits), sino que, en ocasiones, permite obtener una definición consistente y completa que con otras funciones de evaluación (Ganancia en nuestro ejemplo) no se pueden construir.Este es otro sencillo ejemplo en el que los resultados obtenidos por el algoritmo FOIL dependen del heurístico de evaluación que se emplee al construir las reglas. La base de datos de entrada consta de cuatro relaciones:
abuelo(A) = la persona A es un abuelo
padre_de(A, B) = la persona A es padre de B
Los atributos usados en las tuplas de estas relaciones pertenecen al siguiente dominio:
y las tuplas que forman cada relación son las siguientes:
Podemos representar estas relaciones del siguiente modo:
La relación objetivo será abuelo. Hay que hacer notar que en este ejemplo tan pequeño, la longitud de descripción extensional asociada a la relación objetivo es muy pequeña ( ecuación [EC. 2.21] ):
por tanto, sólo serán admisibles descripciones cortas, que no superen esta longitud. Esto hará que sólo con el heurístico Interés* se consiga una definición válida, además de consistente y completa.
Las definiciones construidas con las diferentes funciones de evaluación son las siguientes:
abuelo(X1) :- padre_de(X1, V2), varon(V2)
abuelo(X1) :- padre_de(X1, V2), ...
al aplicar poda por Mínima Longitud de Descripción, finaliza en este punto la construcción de la última cláusula que, además, es eliminada porque su precisión (ver nota de pág. 39 ) es inferior al umbral permitido:
Por tanto, resultaría una definición incompleta (no cubre la tupla +<a1>).
Sin embargo, teniendo en cuenta que el principio de Mínima Longitud de Descripción debe aplicarse para comparar el conjunto cubierto (formado por una única tupla: +<a2>) con la definición intensional, resulta que no se satisface para esta definición:
con lo que no se obtiene ninguna definición intensional válida para la relación abuelo.
1. Según el diccionario de la Real Academia Española ( [RAE, 94] ) la correlación se define como la "correspondencia o relación recíproca entre dos o más cosas o series de cosas; en matemáticas, es la existencia de mayor o menor dependencia mutua entre dos variables aleatorias".
El coeficiente de correlación mide la dependencia entre dos variables cuantitativas ( [Larousse, 96] ); su valor será positivo si las variaciones de ambas son del mismo sentido, negativo en el caso contrario y nulo si las variaciones de uno no parecen seguir en modo alguno las del otro. Se utilizan diversos coeficientes para evidenciar los vínculos que existen entre dos o más fenómenos; el más importante de ellos es el coeficiente de correlación lineal, que es tanto más próximo a +1 o a -1 cuanto más estrecho es el vínculo entre dos variables, y tanto más próximo a 0 cuanto más laxo es.
En nuestro caso, decimos que RI es una medida de la correlación porque cumple las condiciones necesarias para ello:
1) A y B independientes Pro(B|A) = Pro(B) NAB = NA NB / N RI = 0
2) A y B dependientes y varían en mismo sentido Pro(B|A) = 1 NAB = NA = NB RI = 1
3) A y B dependientes y varían en sentido contrario Pro(B|A) = 0 NAB = 0 RI = -1
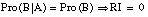
 (probabilidad condicional)
(probabilidad condicional)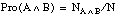 (definición de probabilidad)
(definición de probabilidad)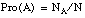
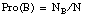
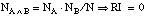 [EC. 3.1]
[EC. 3.1]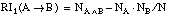 [EC. 3.2]
[EC. 3.2]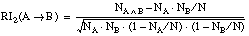 [EC. 3.3]
[EC. 3.3]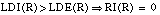
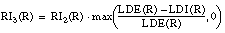 [EC. 3.4]
[EC. 3.4]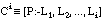
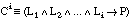
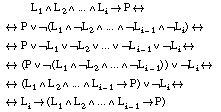
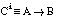
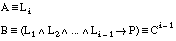
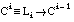
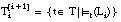 [EC. 3.5]
[EC. 3.5]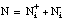 número total de tuplas de Ti
número total de tuplas de Ti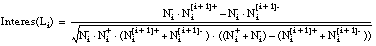 [EC. 3.6]
[EC. 3.6]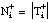
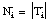
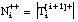
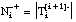
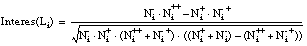 [EC. 3.7]
[EC. 3.7]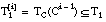
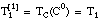
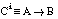
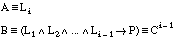
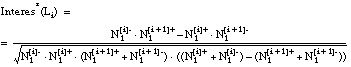 [EC. 3.8]
[EC. 3.8]